

Lisää rakenteisista tietotyypeistä
Union
Union on rakenteinen tietotyyppi joka voi sisältää valikoiman toisilleen vaihtoehtoisia tietotyyppejä. Sen määrittely muistuttaa struct-määrittelyä, mutta toiminta on erilainen. Unionimäärittelyn sisällä esitetyt kentät sijaitsevat kaikki samassa kohtaa muistia, eivät peräkkäin kuten structin tapauksessa. Kun yhteen kenttään kirjoitetaan arvo, muidenkin kenttien sisältö todennäköisesti siis muuttuu.
Unioni on perinteistä tietorakennetta selvästi harvemmin käytetty tietotyyppi, mutta toisinaan sitä näkee käytettävän. Alla oleva esimerkki esittelee kuinka unionia käytetään. Siinä aletaan rakentaa kuvitteellista yksi-ulotteista(!) taulukkolaskentaohjelmaa, jossa on joukko soluja, jotka sisältävät jonkin arvon. Kukin solu voi sisältää joko lukuarvon (num), merkkijonon (label) tai laskukaavan (form). Koska solu voi sisältää vain jonkun näistä kerrallaan, unioni soveltuu tietotyypiksi jolla yhden solun sisältö esitetään. Unionin käyttö on tehokkaampaa kuin esimerkiksi structin, koska se vaatii tilaa vain sen verran, mitä sen suurikokoisin kenttä käyttää.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | #include <stdio.h> #include <string.h> // This structure stores an imaginary formula and two parameters // (here we assume that the operation and two parameters are defined // as small strings) struct formula { char operation[10]; char param1[10]; char param2[10]; }; union u_types { float num; // single number value in spreadsheet cell char label[20]; // text label in spreadsheet cell struct formula form; // formula in spreadsheet cell }; |
Kun unionityyppi on määritelty, sitä käytetään pitkälti samalla tavoin kuin perinteistä tietorakennetta. Alla olevassa esimerkissä käytämme edellä esiteltyä u_types - tyyppistä unionia. Taulukkolaskentaohjelmassamme on 10 solua, jotka nyt tässä tapauksessa varataan vain staattisesti pinosta (rivi 3). Määrittelemme valmiiksi myös yhden kaavan (rivi 4), jonka voi ajatella laskevan keskiarvon solujen A2 ja A3 välillä. Sen jälkeen kopiomme soluun 0 merkkijonon "Header), soluun 1 edellä mainitun kaavan, sekä myöhemmin korvaamme kaavan lukuarvolla 5.
Kuten mitä tahansa tietorakenteita, myös unioneista voi rakentaa sisäkkäisiä rakenteita joko toisten unionien tai struct:ien kanssa. Näinhän olemme tehneen form - kaavan kanssa. Rivillä 12 nähdään kuinka tällaisiin kenttiin viitataan.
On hyvä huomata, että kun rivillä 16 korvaamme solun 1 sisällön lukuarvolla 5, aiemmin mainittua kaavaa ei enää voi käyttää, koska samalle muistialueelle on kirjoitettu uutta sisältöä (eli liukuluku). Koska kaava muodostui merkkijonoista, merkkijonojen sisältö muuttuu tämän sijoituksen seurauksena merkityksettömäksi.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | int main(void) { union u_types sheet[10]; struct formula avg = { "AVG", "A2", "A3" }; // Because t_label is an array, we need to use strcpy strcpy(sheet[0].label, "Header"); // Direct assignment works because this is struct sheet[1].form = avg; printf("stored formula: %s(%s, %s)\n", sheet[1].form.operation, sheet[1].form.param1, sheet[1].form.param2); // This will "overwrite" the formula (partly) sheet[1].num = 5; } |
Unionirakenteesta ei voi sellaisenaan selvittää minkä tyyppinen arvo siihen on kulloisellakin hetkellä tallennettu. Tätä varten ohjelmaan tarvitaankin jokin tapa pitää kirjaa siitä, mikä unionille esitetyistä vaihtoehtoisista tyypeistä on tallennettu. Tämä voi joskus olla ilmeistä ohjelmalogiikasta, tai sitten voidaan käyttää apumuuttujaa, jolla asia esitetään.
Enumeraatiovakiot
Enumeraatiovakioilla voidaan määritellä muuttujia, joiden arvo sisältää yhden vaihtoehtoisista vakioarvoista, joille on määrätty ohjelmassa selkeä (ihmisen ymmärtämä) symboli. Esimerkiksi alla määrittelemme tyypin en_color, jolla voidaan esittää jotain väriä.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | enum en_color { RED, GREEN, BLUE }; void printColor(enum en_color col) { switch(col) { case RED: printf("red\n"); break; case GREEN: printf("green\n"); break; case BLUE: printf("blue\n"); break; } } |
Tämä on ohjelmakoodissa paljon selkeämpää, kuin esimerkiksi koodata väritieto jollain ennalta sovitulla kokonaislukuarvolla. Käytännössä tämä onkin juuri se, mitä kääntäjä enumeraatioille tekee: se korvaa kyseisen symbolin kokonaisluvulla, jota ohjelmoijan ei kuitenkaan välttämättä tarvitse tietää. Oletusarvoisesti kääntäjä numeroi vakiot järjestyksessä 0:sta alkaen. Ohjelmakoodissa haluamme kuitenkin selkeyden vuoksi aina käyttää määrittelemiämme vakioita, kuten on esimerkiksi tehty printColor - funktiossa. Vakioarvoja ei voi sellaisenaan tulostaa (nehän ovat oikeasti vain kokonaislukuja), mutta niiden tulostamiseen voidaan toteuttaa oma funktio, kuten tässä on juurikin tehty.
Ohjelmoija voi halutessaan itsekin määrätä enumeraatiota vastaavat kokonaislukuarvot, kuten esimerkiksi alla:
1 2 3 4 5 6 | /* Type Duration, some durations in seconds */ typedef enum { MINUTE = 60, HOUR = 60 * MINUTE, DAY = 24 * HOUR } Duration; |
Enumeraatiovakioiden avulla voimme nyt parantaa taulukkolaskentaohjelmaamme kaivatulla lisäkentällä: enumeraatiolla, joka kertoo minkä tyyppinen arvo määriteltyyn unioniin on parasta aikaa tallennettu. Määrittelemme siis seuraavat vakioarvot:
1 2 3 4 5 6 | enum en_types { UNSPEC, // union content is unspecified NUMBER, // union stores a number LABEL, // union stores a string number FORMULA // union stores a formula }; |
Yllä olevassa listassa on siis vaihtoehdot kullekin unionin mahdollisesti sisältämälle tyypille, sekä lisäkenttä UNSPEC, joka kertoo että kyseiseen soluun ei ole vielä tallennettu yhtään mitään.
Alla koko tietokantaohjelma enumeraatioilla laajennettuna. Koska kutakin solua kohden tarvitaan nyt kaksi tietoa: varsinaisen arvon sisältävä unioni, sekä vakio joka kertoo solun tilan, joudumme määrittelemään vielä yhden uuden tason rakenteisia tietotyyppejä (struct cell). Nyt sisäkkäitä rakenteita alkaa ollakin jo aika monta, joten esimerkiksi kaavan tulostamisen kanssa (rivi 56) saa olla tarkkana että koko ketju tulee oikein kirjoitettua. Kullakin tasolla kenttiin viitataan samalla syntaksilla riippumatta siitä onko kyseessä struct vai union.
Nyt ohjelma ensiksi alustaa taulukon tyhjäksi, eli kaikki solut UNSPEC-tilaan, sitten asettaa soluun 0 merkkijonon ja soluun 1 kaavan, ja lopuksi tulostaa koko taulukon. Kunkin solun tulostus riippuu siitä minkä tyyppinen arvo siihen on tallennettu.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 | // This structure stores an imaginary formula an two parameters struct formula { char operation[10]; char param1[10]; char param2[10]; }; union u_types { float num; char label[20]; struct formula form; }; enum en_types { UNSPEC, // union content is unspecified NUMBER, // union stores a number LABEL, // union stores a string number FORMULA // union stores a formula }; // one cell in spreadsheet: stores the type of the cell (enum) // and the actual content (union, corresponding type indicated by enum) struct cell { enum en_types type; union u_types value; }; int main() { struct cell sheet[10]; struct formula avg = { "AVG", "A2", "A3" }; int i; for (i = 0; i < 10; i++) { // initialization: all fields unspecified sheet[i].type = UNSPEC; } // Because label is an array, we need to use strcpy sheet[0].type = LABEL; strcpy(sheet[0].value.label, "Header"); // Direct assignment works because this is struct sheet[1].type = FORMULA; sheet[1].value.form = avg; for (i = 0; i < 10; i++) { switch(sheet[i].type) { case LABEL: printf("%s\n", sheet[i].value.label); break; case NUMBER: printf("%f\n", sheet[i].value.num); break; case FORMULA: printf("%s(%s, %s)\n", sheet[1].value.form.operation, sheet[1].value.form.param1, sheet[1].value.form.param2); break; case UNSPEC: printf("--\n"); break; } } } |
Koska enumeraatiot ovat käytännössä vain vakiomuotoisia kokonaislukuja, niitä voi käyttää myös switch-rakenteessa, kuten esimerkissämme on tehty.
Task 01_anydata: Jokudata (2 pts)
Tavoite: Hankkia tuntumaa unioneiden käsittelyyn
Tässä tehtävässä määritellään uusi tietotyyppi AnyData, joka voi pitää sisällään joko tavun (eli char), kokonaisluvun (int) tai double - tyyppisen liukuluvun. AnyData - tietotyyppi määritellään typedef määritelmän avulla, mikä on hyvä huomioida kun tietotyyppiä käytetään.
AnyData on rakenteinen tietotyyppi joka koostuu kahdesta kentästä: type on enumeraatio, joka kertoo mikä kolmesta edellä mainitusta tyypistä rakenteeseen on kulloinkin tallennettu, sekä value on unionirakenne, johon on tallennettu kyseisen tyyppinen arvo. Näet otsakkeesta anydata.h kuinka tyyppi on tarkalleen ottaen määritelty. Lisäksi type - kenttään voi olla tallennettu arvo UNDEF, mikäli rakenteeseen ei ole vielä tallennettu mitää arvoa.
Toteuta seuraavat osat:
a) Aseta arvo
Toteuta funktiot setByte, setInt ja setDouble jotka palauttavat uuden AnyData-tyyppisen objektin paluuarvonaan, perustuen annettuun tyyppiin ja arvoon, joka kyseisen funktion parametrissa on annettu.
b) Tulosta arvo
Toteuta funktio printValue joka tulostaa AnyData:n tallentaman arvon. Tulostusformaatti riippuu muuttujaan asetetun arvon tyypistä. Varsinaiseen tulostukseen sinun täytyy käyttää yhtä anydata.c:ssä valmiiksi annetuista funktioista (printByte, printInt tai printDouble), riippuen muuttujaan tallennetun arvon tyypistä.
Moniulotteiset taulukot
Staattiset taulukot
Olemme toistaiseksi tarkastelleet vain yksiulotteisia taulukoita, mutta C:ssä voi myös olla moniulotteisia taulukoita. Keskitymme lähinnä kaksiulotteisiin taulukoihin esityksen helpottamiseksi, mutta toki ulottuvuuksia voi olla kuinka monta tahansa. Moniulotteisen taulukon voi rakentaa useammalla vaihtoehtoisella tavalla, jotka seuraavassa käydään läpi.
Alla on esimerkki yksinkertaisesta 3x3 kokoisesta staattisesta kaksiulotteisesta taulukosta:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | #include <stdio.h> int main(void) { int matrix[3][3] = {{1,2,3}, {4,5,6}, {7,8,9}}; int i,j; // Print the matrix in rectangular format for (j = 0; j < 3; j++) { for (i = 0; i < 3; i++) { printf("%d ", matrix[j][i]); } printf("\n"); } } |
Rivillä 4 määritellään matrix - kokonaistaulukko, jonka alkusisältö samalla alustetaan. Alustuslista näyttää sisäkkäisiltä yksiulotteisilta taulukoilta, joissa kussakin määritellään yksi taulukon rivi. Alustuslista havainnollistaa myös hyvin sen, että moniulotteinen taulukko on C:ssä käytännössä taulukko, jonka jäsenet ovat toisia taulukoita.
Ylläoleva ohjelma tulostaa taulukon 3x3 - muotoon ruudulle kahden sisäkkäisen for-silmukan avulla. Esimerkistä nähdään että syntaksi on samanlainen kuin yksiulotteisissa taulukoissakin, nyt vain tarvitaan kahdet hakasulkeet taulukon indeksoimiseksi (tai useammat, mikäli ulottuvuuksia on useampia). Joistain toisista kielistä poiketen indeksit on sijoitettava eri hakasulkeiden sisään, eikä niitä esimerkiksi eroteta pilkulla.
Edellä mainitun kaltainen taulukko sijoittuu peräkkäisiin paikkoihin muistissa. Se siis muistuttaa yhtä 9 alkion taulukkoa (ja voitaisiin helposti sellaisen pohjalta luoda).
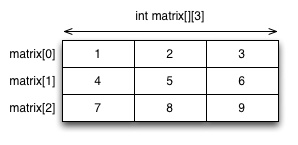
Kaksiulotteisen taulukon käyttäminen funktioparametrissa vaatii oman, hieman hankalan näköisen notaation. Alla oleva esimerkki näyttää miten se tämän esimerkin taulukon tapauksessa kävisi, funktiossa printArray. Tietotyypin määrittelyssä pitää kertoa "sisemmän" taulukon sarakkeiden määrä, jotta funktio osaa parsia muistissa olevan taulukon oikealla tavalla: funktion on tiedettävä mistä alkiosta alkaa uusi rivi. Sen sijaan ulomman taulukon koko ei ole tarvittava tieto, vaan ulompi taulukko toimii kuten C:n yksiulotteinen taulukko, myös kaikkine sudenkuoppineen: voit indeksoida sen yli ja aiheuttaa siten ongelmia ohjelman ajonaikaiselle toiminnaklle.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <stdio.h> void printArray(int arr[][3]) { int i,j; // Print the matrix in rectangular format for (j = 0; j < 3; j++) { for (i = 0; i < 3; i++) { printf("%d ", arr[j][i]); } printf("\n"); } } int main(void) { int matrix[3][3] = {{1,2,3}, {4,5,6}, {7,8,9}}; printArray(matrix); } |
Toinen tapa rakentaa kaksiulotteinen taulukko on laatia taulukko osoittimia, jossa kukin osoitin vuorostaan viittaa taulukkoon. Tässä mallissa on ainakin pari etua: 1) funktiorajapinnassa voidaan käyttää tietotyyppinä toisen asteen osoitinta, joka sallii vaihtuvan kokoiset taulukot; 2) tarvittaessa taulukon eri rivit voivat olla eri kokoisia, eli niillä voi olla eri määrä alkioita. Tämä tulee usein kyseessä merkkijonotaulukoiden kanssa: nehän ovat kaksiulotteinen taulukko merkkejä.
Alla olevassa esimerkissä laaditaan edellä kuvatun tapainen taulukko arr_p. Se asetetaan käyttäen aiemmin määrittelemäämme matrix - taulukkoa. Kukin arr_p:n alkio on osoitin yhteen taulukon riviin. Esimerkissä näkyy myös, kuinka tällaista taulukkoa käytetään funktion yhteydessä. Funktion parametreina on nyt myös taulukon koko molemmissa ulottuvuuksissa, koska periaatteessa se voi vaihdella dynaamisesti, eikä funktiossa välttämättä tiedetä sitä. Oheinen kuva esittää ohjelman asettamaa tilannetta muistissa.
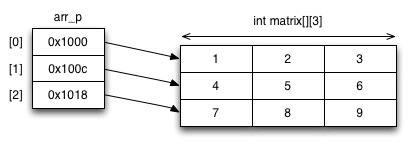
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | #include <stdio.h> void printArray(int **arr, int xs, int ys) { int i,j; // Print the matrix in rectangular format for (j = 0; j < ys; j++) { for (i = 0; i < xs; i++) { printf("%d ", arr[j][i]); } printf("\n"); } } int main(void) { int matrix[3][3] = {{1,2,3}, {4,5,6}, {7,8,9}}; int *arr_p[3]; for (int i = 0; i < 3; i++) { arr_p[i] = matrix[i]; } printArray(arr_p, 3, 3); } |
On hyvä huomioida, että arr_p[0] ja matrix[0] ovat eri
tietotyyppejä. Tämä käy ilmi esimerkiksi silloin, kun vertailemme
sizeof - operaattorin tuottamia kokoja kyseisille arvoille:
sizeof(arr_p[0]):n palauttama koko on yhden osoittimen koko (eli 8
tai 4 tavua järjestelmästä riippuen), kun taas sizeof(matrix[0]) on
kooltaan tyypillisesti 12 tavua (kolmen kokonaisluvun vaatima
tila). Koska taulukon sijoittaminen osoitinmuuttujaan onnistuu
helposti, rivillä 19 tehtävä sijoitus on mahdollinen vaikka kyseessä
on kaksi eri tietotyyppiä. printArray() - funktio toimii vain
arr_p - taulukon kanssa.
Dynaamisesti varatut moniulotteiset taulukot
Moniulotteisia taulukoita voidaan varata myös dynaamisesti keosta käyttäen malloc - funktiota. Tällöinkin taulukko voidaan laatia useilla vaihtoehtoisilla tavoilla, mutta tässä yhteydessä keskitymme suoraviivaiseen järjestelyyn: esimerkiksi kaksiulotteinen taulukko rakennetaan siten, että ensin varaamme tarpeeksi muistia taulukolle osoittimia. Nämä esittävät taulukon "rivejä". Tämän jälkeen kuhunkin alkioon sijoitetaan osoitin, joka saadaan uudella malloc-kutsulla, jossa varaamme tilaa taulukon yhdelle riville. malloc - kutsuja tehdään siis yksi kutakin riviä kohden, sekä lisäksi yksi taulukko , johon nämä osoittimet talletetaan.
Seuraavassa esimerkki siitä miten tämä tehdään:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | #include <stdio.h> #include <stdlib.h> void printArray(int **arr, int xs, int ys) { int i,j; // Print the matrix in rectangular format for (j = 0; j < ys; j++) { for (i = 0; i < xs; i++) { printf("%2d ", arr[j][i]); } printf("\n"); } } int main(void) { int **arr_p; int xdim = 4; int ydim = 5; // first allocate array that points to arrays of rows // (notice the data type in sizeof operation) arr_p = malloc(ydim * sizeof(int *)); if (!arr_p) return -1; // memory allocation failed for (int j = 0; j < ydim; j++) { arr_p[j] = malloc(xdim * sizeof(int)); if (!arr_p[j]) { // memory allocation failed, release memory // will have to go through previously allocated rows for (int i = 0; i < j; i++) { free(arr_p[i]); } free(arr_p); return -1; } for (int i = 0; i < xdim; i++) { // fill matrix with values, multiplication table arr_p[j][i] = (i+1) * (j+1); } } printArray(arr_p, xdim, ydim); // release the memory for (int j = 0; j < ydim; j++) { free(arr_p[j]); } free(arr_p); } |
Tällainen taulukko sijoittuisi muistiin jotenkin seuraavaan tapaan:
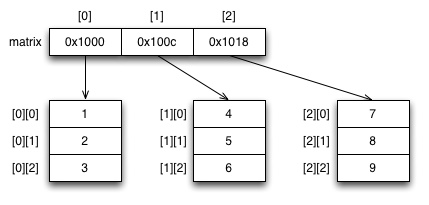
Yllä olevassa esimerkissä printArray() toimii kuten aiemminkin toisen asteen osoittimien tapaukessa.
Kun taulukkoa varataan, kannattaa olla tarkkana varattavan muistin määrän kanssa: edelleenkin meidän pitää tietää varattavan taulukon koko, ja kertoa se yhden alkion tarvitsemalla koolla. Nyt pitää vain muistaa, että ensimmäisessä varauksessa tietotyyppi onkin osoitin, eikä pelkästään kokonaisluku, mikä käy ilmi rivillä 22.
Kannattaa myös huomioida mitä muuttujia kunkin muistinvarauksen
yhteydessä käytetään, ja kuinka indeksointioperaattoreita käytetään
kussakin yhteydessä. Rivillä 22 indeksointia ei käytetä ollenkaan, kun
rivejä varten varataan tilaa. Tämän jälkeen käytämme (esimerkiksi
rivillä 27) vain yhtä indeksiä, kun varataan riveille tilaa. Vasta kun
varsinaisiin alkioihin sijoitetaan arvoja tai niitä käytetään muuten
lausekkeissa, käytetään kahta indeksiä. Tämä voi tuntua
monimutkaiselta, mutta kenties hahmottuu paremmin, kun palautat
mieliin miten yksiulotteisen taulukon varaus toimi, ja mitä
tietotyyppejä arr_p (int**), arr_p[1] (int *), ja
arr_p[1][1] (int) oikeastaan ovat.
On myös hyvä tiedostaa, että osoittimia voi pinota
päällekkäin. int** on validi tietotyyppi: se on osoitin johonkin
toiseen osoittimeen, joka loppujen lopuksi viittaa
kokonaislukuun. Kuten yksiulotteisenkin taulukon tapauksessa, taulukon
indeksointi on samalla viittaus osoittimeen. Siten arr_p[i]:n
tietotyyppi onkin jo int*, koska arr_p[i] on sama kuin *(arr_p +
i), eli tietotyypistä tipahtaa yksi tähti pois. Vastaavasti
arr_p[j][i]:stä tipahtaa jälleen yksi tähti pois (koska se on sama
kuin *(*(arr + j) + i)), jolloin viittaammekin jo normaaliin
kokonaislukuun.
Samalla tavoin voimme yleistää useampiin ulottuvuuksiin: tähtien määrä
tietotyypeissä vain kasvaa vastaavasti. Myös int**** on toimiva
tietotyyppi, joskin se harvoin ilmentää hyvää ohjelmointityyliä.
Merkkijonotaulukot
Yleinen esimerkki kaksiulotteisesta taulukosta on taulukko merkkijonoja, joka itse asiassa on kaksiulotteinen taulukko merkkejä. Tällöin taulukon eri rivien pituus voi vaihdella siihen tallennetun merkkijonon mukaan (tai sitten taulukkoa varatessa on oletettu jonkinlaista maksimipituutta kullekin merkkijonolle).
Seuraavassa esimerkissä on merkkijonotaulukko, jossa on 12 jäsentä.
1 2 3 4 5 6 7 8 9 10 11 | #include <stdio.h> int main(void) { const char *months[] = { "January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December" }; for (int i = 0; i < 12; i++) { printf("%s\n", months[i]); } } |
Merkkijonot on varattu kirjoitussuojatusta osasta muistia
vakiomerkkijonoina, joten on aiheellista käyttää const määrettä
muuttujan määrittelyssä. Tämä kertoo kääntäjälle, että taulukon
alkioihin ei voi kirjoittaa. Taulukon määrittelystä ei välttämättä
heti ilmene että se olisi kaksiulotteinen taulukko, mutta lausekkeella
months[j][i] voidaan viitata yksittäiseen merkkiin j:nnessä taulukon
merkkijonossa.
Koska rivillä 9 olevassa printf - funktiokutsussa käytetään %s -
muotoilumäärettä, parametriksi oletetaan char * - tyyppistä
arvoa. Siksi parametrissa riittää vain yksi indeksointioperaattori
(koska esim. months[i][0] olisi tyypiltään char, eli yksi merkki).
Yllä olevassa esimerkissä olisimme voineet määritellä merkkijonot myös muokattaviksi. Tällöin kuukaudet olisi pitänyt määritellä seuraavasti:
1 2 3 | char months[12][20] = { "January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December" }; |
Tällöin merkkijonojen maksimipituus pitää antaa. Tämä vastaa rakenteeltaan staattista taulukkoa jollainen tämän luvun alussa esitettiin. Nyt merkkijonot sijaitsisivat peräkkäisissä osissa muistia, vieden kukin 20 tavua tilaa.
Task 02_life: Game of Life (4 pts)
Tavoite: Harjoitella dynaamisesti varattavia kaksiulotteisia taulukoita osana pientä peliä.
Game of Life on perinteinen "peli", jossa lähinnä tietokone pelaa muuntamalla kaksiulotteista pelikenttää tiettyjen sääntöjen perusteella. Game of Life:n kaksiulotteinen pelikenttä muodostuu soluista, jotka voivat olla kahdessa eri tilassa: elossa tai kuolleita. Pelikenttää päivitetään askel (eli sukupolvi) kerrallaan siten että kunkin solun tila voi muuttua riippuen sen naapurisolujen tilasta. Peli jatkuu näin periaatteessa ikuisesti, kunnes joku keskeyttää sen toiminnan.
Kunkin solun tilaa säädetään seuraavien sääntöjen perusteella:
-
Jos elossa olevalla solulla on vähemmän kuin kaksi elossa olevaa naapuria, solu kuolee.
-
Jos elossa olevalla solulla on kaksi tai kolme elossa olevaa naapuria, soluu säilyy hengissä.
-
Jos elossa olevalla solulla on enemmän kuin kolme elossa olevaa naapuria, solu kuolee.
-
Mikäli kuolleella solulla on tasan kolme elossa olevaa naapuria, solu muuttuu elolliseksi
Myös kulmittaiset solut lasketaan naapureiksi, eli kullakin solulla (joka ei ole pelikentän reunassa) on 8 naapuria. Huomioi että pelikentän reunassa olevat solut pitää käsitellä erikoistapauksina: et saa yrittää käsitellä pelikentän ulkopuolella olevia alueita.
Pelikentän tilamuutosten tulee tapahtua loogisesti saman aikaisesti, eli kunkin solun tilan tulee riippua edellisen sukupolven tilanteesta.
Esimerkiksi seuraavan näköinen pelikenttä (jossa '*' merkitsee elävää solua)
.......... .**.***... .**......* .*.*.....* ........*.
tulisi seuraavassa sukupolvessa muuttua tämän näköiseksi:
.....*.... .***.*.... *...**.... .*......** ..........
Aiheeseen liittyvä wikipedia-sivu kertoo aiheesta lisätietoa.
Tässä harjoituksessa sinun tulee toteuttaa seuraavat osat, joita tarvitaan pelin pyörittämiseen. main - funktio src/main.c:ssä sisältää pelin päärakenteen, josta kutsutaan toteuttamiasi funktioita sukupolvi kerrallaan kunnes päätät lopettaa pelin.
Harjoituksessa on seuraavat osat:
a) Luo ja vapauta pelikenttä
Toteuta funktio createField, joka varaa tarvittavan muistin Field - tietorakenteelle, johon pelikenttä tallennetaan. Pelikentän koko määritellään parametreilla xsize ja ysize. Aluksi kukin kentän solu tulee asettaa DEAD - tilaan, sekä lisäksi sinun tulee asettaa xsize ja ysize - kentät tietorakenteessa saamiesi parametrien mukaisiksi.
Tehtävän testit olettavat, että varaat ensin kaksiulotteisen alueen rivit ysize - parametrissa annetun koon mukaisesti, ja sen jälkeen kunkin rivin, joiden koko määritellään xsize - parametrissa.
Sinun pitää lisäksi toteuttaa funktio releaseField, joka vapauttaa varaamasi muistin. On tärkeää että toteutat tämän funktion aikaisessa vaiheessa, koska tehtävän testit tulevat käyttämään sitä jatkossa muistin vapauttamiseen. Toisin sanoen Valgrind ei ole tyytyväinen (ja estää pisteiden saamisen) ennenkuin tämä funktio ei ole toteutettu.
b) Alusta kenttä
Toteuta funktio initField, joka muuttaa annetun määrän (n) soluja ALIVE-tilaan. Voit itse määrittää millä perusteella muutettavat solut valitaan. Yksi vaihtoehto on käyttää rand - funktiota, ja valita solut satunnaisesti. Tärkeintä on että funktion jälkeen tasan n solua on vaihtanut tilaansa.
c) Tulosta kenttä
Toteuta funktio printField joka tulostaa kentän sen hetkisen tilan ruudulle. Kuolleet solut tulee merkata pisteellä ('.'), ja elossa olevat solut tähdellä ('*'). Solujen välissä ei ole tyhjiä välejä, ja kukin rivi loppuu rivinvaihtomerkkiin ('\n'), mukaanlukien viimeinen rivi. Tulosteen tulisi siis näyttää samanlaiselta, kuin yllä annetuissa esimerkeissä.
d) Käsittele sukupolvi
Toteuta funktio tick joka siirtää pelikentän tilaa yhden sukupolven verran eteenpäin noudattaen edellä annettuja sääntöjä. Muista, että kunkin solun tilan tulee riippua edellisestä sukupolvesta, eli kaikki solut muuttuvat loogisesti "samaan aikaan" (vaikka ohjelmassa joudut käsittelemään ne yksi kerrallaan). Voit joutua esimerkiksi tilapäisesti taltioimaan kaksi kopiota pelikentästä: edellisen sukupolven ja uuden sukupolven.
(Mikäli varaat uutta muistia tässä funktiossa, muista huolehtia myös muistin vapautuksesta)
Komentoriviargumentit
Perinteisille komentoriviltä (tai komentoskriptistä) käynnistettäville ohjelmille voi antaa lisätietoa komentoriviargumenttien avulla. Kun ohjelma käynnistetään, ajettavan binääritiedoston nimi annetaan komentorivillä. Samalla ohjelman nimen perään voi antaa vaihtuvan määrän argumentteja, joilla jotenkin ohjataan ohjelman toimintaa. Nämä argumentit välitetään ohjelmalle main - funktion parametreina.
Toistaiseksi näkemissämme ohjelmissa main - funktiossa ei ole ollut parametreja, mutta funktiosta on olemassa myös toinen muoto, jossa on kaksi parametria: taulukko merkkijonoja, sekä tämän taulukon sisältämien merkkijonojen lukumäärä. Tätä funktion määrittelyä käytetään silloin, kun haluamme selvittää onko ohjelmalle annettu komentoriviargumenttejä käynnistyksen yhteydessä.
Seuraava ohjelma saa main - funktion argc - argumenttiin annettujen komentoriviparametrien lukumäärän, sekä argv - taulukkoon annetut komentoriviparametrit.
1 2 3 4 5 6 7 8 9 | #include <stdio.h> int main(int argc, char *argv[]) { printf("This program was called with %d parameters\n", argc); printf("They were (including the program name itself):\n"); for (int i = 0; i < argc; i++) { printf("%s\n", argv[i]); } } |
Järjestelmä parsii komentorivisyötteen siten, että kukin annettu komentoriviargumentti on nollaan päättyvä merkkijono, jotka siis annetaan main - funktiolle funktion argumenttina. Jos ajamme komentorivillä ohjelman program, jolle annamme kolme argumenttiä seuraavasti:
./program one two three
argc:n arvo tulee olemaan 4, ja argv:n sisältö seuraavanlainen: {
"./program", "one", "two", "three" }. Ohjelman nimi siis sisältyy
merkkijonotaulukkoon sen ensimmäisenä argumenttina.
Usein argumentteina annetaan komentorivioptioita, jotka voivat olla
vapaassa järjestyksessä. Optiot alkavat yleensä viivamerkillä (-)
jota seuraa yksi tai useampi merkki. Optiota voi lisäksi seurata
parametri joka sitä määrittää. Esimerkiksi seuraavassa tail -
komennossa:
tail -f -q -n 10 file.txt
on kolme optiota, joista 'f' ja 'q' - optioilla ei ole parametreja, mutta 'n' - optio saa parametrikseen numeron 10. Lopuksi komentorivillä annetaan vielä normaalina argumenttinä käsiteltävän tiedoston nimi. Optiot voi antaa vapaassa järjestyksessä. Optioiden käsittelyyn on C:n standardikirjastossa eräitä valmiita funktioita (esim. getopt), joita ei kuitenkaan tämä kurssin piirissä tarvita.
Task 03_strarray: Merkkijonotaulukko (4 pts)
Tavoite: Harjoittele dynaamisesti varattavan taulukon käyttöä dynaamisesti varattavien merkkijonojen kanssa
Tässä harjoituksessa käsitellään taulukkoa, jossa on osoittimia merkkijonoihin, jotka on varattu dynaamisesti. Taulukon viimeinen alkio merkitään NULL-osoittimella, toisin sanoen tyhjässä taulukossa on siinäkin yksi alkio, nimittäin kyseinen NULL-osoitin.
Sinun tulee toteuttaa seuraavat funktiot:
a) Alusta taulukko
Toteuta funktio init_array, joka varaa tilan ja alustaa merkkijonotaulukon siten, että siinä on ensimmäisenä alkiona NULL-osoitin.
Toteuta lisäksi funktio free_strings joka vapauttaa taulukkoon tallennettujen merkkijonojen käyttämän tilan, sekä osoitintaulukon itsessään. Tässä tehtäväkohdassa merkkijonoja ei vielä ole taulukkoon tallennettu, mutta kannatta huomioida funktiota toteuttaessa, että seuraavissa kohdissa taulukkoon tulee myös merkkijonoja.
Tehtävän testit käyttävät free_strings - funktiota tilan vapauttamiseen, joten se kannattaa toteuttaa heti alussa, koska muuten muistivuodoista johtuvat Valgrind-virheet estävät tehtävien läpäisyn.
b) Lisää merkkijono
Toteuta funktio add_string joka lisää annetun merkkijonon
taulukkoon. Huomaa että parametrina tuleva merkkijono on const char
* - tyypiä, mutta taulukon jäsenten tulee olla muokattavissa. Siksi
pelkkä osoittimen kopiointi ei riitä, vaan sinun tulee kopioida koko
merkkijono sille varattuun tilaan. Kun muutat taulukon kokoa, muista
että sen lopusta tulee aina löytyä NULL-osoitin.
c) Muuta pieniksi
Toteuta funktio make_lower joka muuntaa kaikki taulukon merkkijonoissa olevat kirjainmerkit pieniksi kirjaimiksi. Tässähän voit käyttää hyväksi tolower - funktiota, joka muuntaa annetun merkin.
d) Järjestä taulukko
Toteuta funktio sort_strings joka järjestää taulukossa olevat merkkijonot aakkosjärjestykseen. Voit olettaa että strcmp - funktiota tuottaa oikean järjestyksen. Muista että strcmp palauttaa sekä pienempiä että suurempia arvoja kuin 0, riippuen merkkijonojen keskinäisestä järjestyksestä: kun vertailuoperaatio on negatiiivinen, ensimmäisen merkkijonon tulee sijoittua ennen jälkimmäistä (ja päinvastoin).
Olet myös harjoitellut alkioiden järjestämistä kierroksella 2. Voit todennäköisesti käyttää jossain määrin hyväksi silloin toteuttamaasi algoritmia.
Bittioperaatiot
Binäärijärjestelmä
Kaksikantaisessa binäärijärjestelmässä lukuarvot merkitään ykkösten ja nollien avulla (eli bitteinä). Koska prosessoreissa ja digitaalipiireissä arvot esitetään kahtena eri jännitetasona, binäärijärjestelmä on perinteisesti tärkeä abstraktio varsinkin matalan tason (eli järjestelmää lähellä tapahtuvassa) ohjelmoinnissa. Tietokonejärjestelmissä kaikki arvot tallennetaankin bittiyhdistelmien kombinaationa, vaikka ohjelmoija ei tätä välttämättä usein näekään.
Vaikka C-kieli (ja kaikki muutkin ohjelmointikielet) tarjoavat hyvät välineet kokonaislukujen tai liukulukujen käsittelyyn sellaisenaan, joskus -- varsinkin matalan tason ohjelmoinnissa -- on tarpeen käsitellä tietoa bittitasolla. Esimerkiksi tietoliikenne- ja laitteistorajapinnat saattavat vaatia yksittäisten bittien käsittelyä sen sijaan että aina käsiteltäisiin kokonaisia 8-, 16- tai 32-bittisiä arvoja.
C-kielessä hankaluutena on se, että standardi ei tue binäärivakioiden
esittämistä sellaisenaan, vaikka muuten kielessä onkin tuki bittitason
operaatioihin. Jos haluamme esittää jonkun tietyn bittikombinaation,
meidän onkin keksittävä sitä vastaava kokonaisluku, jota voidaan
käyttää lausekkeissa. Tätä varten on usein helpompi käyttää
heksadesimaali- (eli 16-kantaista) esitysmuotoa, koska tällöin kukin
lukuarvon merkki vastaa aina neljän bitin yhdistelmää. Desimaaliluvun
muuntaminen binääriluvuksi on usein
vaikeampaa. Heksadesimaaliluvuissahan oli käytössä numeroiden 0-9
lisäksi kirjaimet A-F, jolloin voidaan esittää 16 eri
lukuarvoa. C-kielessä heksadesimaalivakiot erotetaan siten, että
niiden edessä on 0x. Esimerkiksi 0xB9 esittää yhtä 8-bittistä
arvoa, joka desimaaliesityksenä olisi 185 ja binääriesityksenä (jota C
ei siis sellaisenaan tue) 1011 1001.
Alla oleva kaavio esittää joukon lukuarvoja desimaali-, heksdesimaali- ja binääriesityksenä.
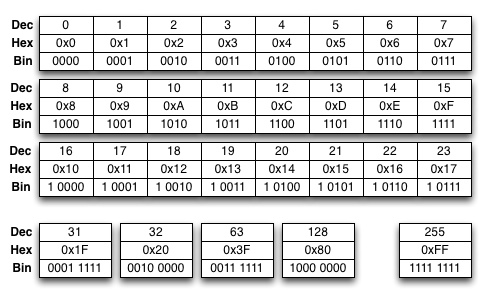
Kaavio rajoittuu 8-bittisiin arvoihin, mutta suurempia lukuarvoja on helppo muodostaa yhdistelemällä heksadesimaaliarvoja ja niitä vastaavaa binääriesitystä. Esimerkiksi 16-bittinen (unsigned short) heksadesimaaliluku 0xD2A0 olisi binäärimuodossa 1101 0010 1010 0000. Kyseisen lukuarvon muuntaminen desimaaliluvuksi onkin jo vaikeampaa päässälaskuna (mutta desimaaliesitys olisi 53920).
Binääriesitystä luetaan samassa järjestyksessä kuin esimerkiksi desimaaliesitystä: vähiten merkitsevä bitti on oikealla ja eniten merkitsevä bitti vasemmalla. Kun bittiyhdistelmää muunnetaan kokonaisluvuksi, kunkin bitin "arvo" on kaksi kertaa suurempi kuin sitä oikealla puolella olevan bitin arvo. Kaavio havainnollistanee tätä parhaiten.
Bittitason operaattorit
Kun lukuarvoja käsitellään yksittäisten bittien tasolla, käytetään tyypillisesti bittitason operaatioita "ja", "tai", "ekslusiivinen tai", ja "ei" (eli komplementti). Koska C-kielessä pienin käytettävissä oleva tietotyyppi on 8-bittinen char (tai unsigned char), bittioperaatioissa käsitellään aina useamman bittin ryppäitä. Bittitason operaatioissa laskun kohteena olevia arvoja käydään läpi bitti kerrallaan, tuottamalla lopputulokseksi operaation synnyttämä bittikombinaatio.
C-kielessä käytössä ovat seuraavat bittioperaattorit
-
bittitason JA (&):
À & Btuottaa tulokseen bitin 1 silloin kun vastaavat bitit arvoissa A ja B ovat molemmat 1, muuten tuloksena tulee 0. -
bittitason TAI (|).
À | Btuottaa tulokseen bitin 1 silloin kun edes joko A:ssa tai B:ssä vastaava bitti on 1. Vain silloin mikäli kyseinen bitti on sekä A:ssa että B:ssä 0, tulokseen tulee 0-bitti. -
bittitason ekslusiivinen TAI (^).
A ^ Btuottaa tulokseen bitin 1 silloin, kun A:ssa ja B:ssä vain toisessa vastaava bitti on asetettuna, mutta toisessa ei. Tätä voi verrata 1-bittiseen summalaskuun: jos molemissa arvoissa kyseinen bitti sisältää saman arvon, lopputulokseen tulee 0 vastaavalle paikalle. -
yhden komplementti ("EI"):
~Avaihtaa kohteena olevaan arvon bittien tilan päinvastaiseksi.
On tärkeää huomatta, että yllä esitellyt bittitason operaattorit ovat
eri operaattoreita, kun esimerkiksi vertailulausekkeissa tyypillisesti
käytettävät loogiset operaattorit (&&, ||, !). Loogiset
operaattorit tuottavat aina joko kokonaisluvun 1 tai 0, kun taas
bittioperaattorit tuottavat lukuarvon, joka muodostuu käsittelemällä
operandien bittejä edellä kuvatuilla tavoilla. Bittioperaattorin ja
loogisen operaattorin sekoittaminen ei välttämättä ilmene
käännösvaiheessa mitenkään, koska kummassakin tapauksessa ne toimivat
osana lausekkeita normaalisti, vaikka tuloksena onkin eri arvo.
Alla olevat kaavio pyrkii havainnollistamaan, miten edellä mainitut operaattorit toimivat kahden unsigned char tyyppisen arvon (0x69 ja 0xCA) välillä.
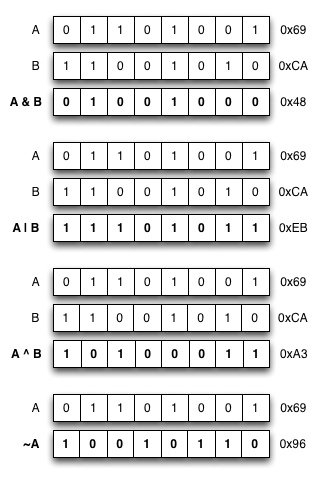
C koodissa vastaavat operaatiot voisivat toimia esimerkiksi seuraavalla tavalla:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <stdio.h> int main(void) { unsigned char a = 0x69; // 01101001 unsigned char b = 0xca; // 11001010 printf("a & b = %02x\n", a & b); unsigned char c = a | b; printf("a | b = %02x\n", c); b ^= a; // b = b ^ a printf("a ^ b = %02x\n", b); printf("~a = %02x\n", ~a); printf("~a & 0xff = %02x\n", ~a & 0xff); } |
Yllä oleva ohjelma tulostaisi:
a & b = 48 a | b = eb a ^ b = a3 ~a = ffffff96 ~a & 0xff = 96
Operaation ~a tulos näyttää yllättävältä, mutta liittyy siihen, että
C-kielessä laskuoperaatioiden yhteydessä arvot käsitellään int -
tyyppisenä kokonaislukuna ("integral promotion"): esimerkiksi char
muutetaan siis tilapäisesti 32-bittiseksi yllä olevassa
esimerkissä. Normaalisti muiden operaatioiden yhteydessä tätä ei
useinkaan huomaa, mutta kun bittien tila vaihdetaan päinvastaiseksi,
nämä lisätyt bitit vaikuttavat lopputulokseen. Toisaalta
JA-bittioperaatiolla (rivi 17), voimme suodattaa "ylimääräiset" bitit
jälleen pois.
Edellä esiteltyjen loogisten operaattoreiden lisäksi toisinaan
käytetään bittien siirto-operaatioita. Operaattori << siirtää
vasempana operandina olevan arvon bittejä oikealla puolella annetun
määrän vasemmalle. Vastaavasti operaattori >> siirtää bittejä
annetun määrän oikealle. Operaatioiden tuloksena lukualueelta pois
siirrettyjen bittien sisältämä tietosisältö menetetään. Toiselta
puolelta tilalle tulee aina 0-bittejä. Esimerkiksi A << 1 siirtää
A:n bittejä yhden askelen vasemmalle, ja A << 4 neljä askelta
vasemmalle.
Alla oleva kaavio havainnollistaa miten nämä operaatiot toimivat:
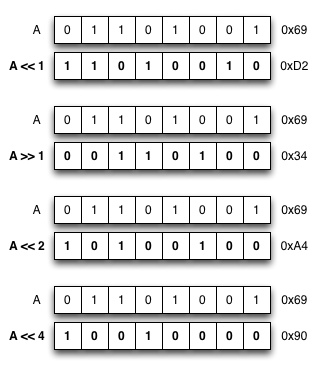
Edellä mainittuja operaatioita käytetään alla olevassa funktiossa printBits, joka käyttä bittisiirto-operaatioita yhdessä loogisen JA-operaation kanssa tulostaakseen annetun unsigned char tyyppisen arvon binääriesityksenä.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | #include <stdio.h> void printBits(unsigned char value) { for (int i = 7; i >= 0; i--) { // (1 << i) generates value where only i'th bit is set // value & (1 << i)) is non-zero only if i'th bit is set in value if (value & (1 << i)) printf("1"); else printf("0"); } } int main(void) { unsigned char a = 0x69; printf("0x69 = "); printBits(a); printf("\n0x69 << 2 = "); printBits(a << 2); printf("\n"); } |
Ohjelma tulostaa:
0x69 = 01101001 0x69 << 2 = 10100100
Bittimaskit
Kun ohjelmassa käsitellään yksittäisiä bittejä tai niiden yhdistelmiä, puhutaan "bittimaskeista". Tyypillisesti näitä käytetään JA tai TAI - operaatioiden yhteydessä. Esimerkiksi JA-operaatiolla voidaan testata, onko jokin tietty bitti päällä vai ei. Voidaan esimerkiksi olettaa että jossain muuttujassa kullekin bitille on määritelty jokin erikoismerkitys, jonka olemassaoloa halutaan testata.
Alla tämänkaltainen esimerkki:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | #include <stdio.h> int main(void) { unsigned char a = 0x36; // 00110110 if (a & 0x2) { // Second bit is set, true in this case } if (a & 0x1) { // First bit is set, not true in this case } if (a & 0xf0) { // are any of the highest four bits set? // convert the highest four bits to integer int b = (a & 0xf0) >> 4; // b == 3 } } |
Yllä olevien if-lauseiden ehdot ovat tosia vain silloin, kun muuttujassa a vastaavat bitit on asetettuna.
Usein puhutaan "lipuista", kun yhden muuttujan kutakin bittiä käytetään ilmaisemaan jonkun ehdon tai ominaisuuden voimassaoloa. Näin saamme pakattua esimerkiksi unsigned char - tyyppiseen arvoon kahdeksan eri lippua, jotka esittävät jotain ominaisuutta ohjelmassa. Esimerkiksi tietoliikenneprotokollissa, joissa pyritään käyttämään käytettävissä olevan kapasiteetti mahdollisimman tehokkaasti, käytetään usein tätä mekanismia pakkaamaan informaatiota pieneen tilaan.
Esimerkkinä lippujen käytöstä voimme tarkastella seuraavaa ohjelmaa, joka käsittelee tiedostoa. Tiedostolle on määritelty käyttöoikeudet, esimerkiksi voidaanko siitä lukea, voidaanko tiedostoon kirjoittaa tai voidaanko se suorittaa. Hyvää tyyliä on lisäksi määritellä vakiomuuttujat esittämään eri bittiarvoja, jolloin ohjelmakoodi on selkeämpi ymmärtää, kuin että heksadesimaalilukuja käytettäisiin sellaisenaan. Ohjelmassa huomataan, kuinka TAI-operaatiolla voidaan yhdistää bittimaskeja.
Kun käyttöoikeuksia tulostetaan, käytämme %x - muotoilumäärettä, jotta luvut tulostuvat heksadesimaalimuotoisina. Tällöin bittien sisältö on helpompi hahmottaa.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | #include <stdio.h> typedef unsigned char MyFlags; // Owner permissions const MyFlags CanRead = 0x1; const MyFlags CanWrite = 0x2; const MyFlags CanExecute = 0x4; const MyFlags CanDelete = 0x8; // Group permissions const MyFlags GroupCanRead = CanRead << 4; // 0x10 const MyFlags GroupCanWrite = CanWrite << 4; // 0x20 const MyFlags GroupCanExecute = CanExecute << 4; // 0x40 const MyFlags GroupCanDelete = CanDelete << 4; // 0x80 typedef struct { const char *name; MyFlags perms; } File; int main(void) { File fileA; fileA.name = "File 1"; fileA.perms = CanRead | CanWrite; // can read and write, but not execute printf("flags 1: %02x\n", fileA.perms); if (fileA.perms & CanRead) { printf("reading is possible\n"); } if (fileA.perms & GroupCanRead) { // Group cannot read, so we can't get here printf("group reading is possible\n"); } fileA.perms |= GroupCanRead; // now also group can read printf("flags 2: %02x\n", fileA.perms); // zeroing CanWrite and GroupCanWrite fileA.perms &= ~(CanWrite | GroupCanWrite); // print the final state of flags printf("flags 3: %02x\n", fileA.perms); } |
Yllä oleva ohjelma tulostaa seuraavaa:
flags 1: 03 reading is possible flags 2: 13 flags 3: 11
Task 04_ip: IP-otsake (4 pts)
Tavoite: Harjoittele binäärioperaatioita
IP-protokollaa käytetään miltei kaikessa tämän päivän Internet-kommunikaatiossa. Wikipediassa on tiivis perustietopaketti IP-protokollasta ja sen ominaisuuksista. Internetissä tieto kulkee paketeissa, joiden alussa on 20 tavua pitkä IP-otsake. Otsakkeen rakenne on dokumentoitu wikipedia-artikkelissa. Otsakkeessa on haluttu pakata tarvittava tieto mahdollisimman tiiviseen tilaan kommunikoinnin tehostamiseksi, joten 16- ja 8-bittisten kenttien lisäksi otsakkeessa on kenttiä jotka vievät tai yhden tai muutaman bitin.
Tehtävänäsi on toteuttaa funktio, joka rakentavat struct ipHeader:ssa annetuista otsaketiedoista 20 tavun mittaisen pakettiotsakkeen, ja toisaalta funktio, joka purkaa pakettiotsakkeen helpommin käsiteltävään edellä mainittuun C-tietorakenteeseen. Koska osa otsakkeen kentistä vie tilaa vain muutaman bitin, joudut soveltamaan binäärioperaatioita osaan otsakekentistä.
Et voi vain kopioida tietorakennetta otsakkeeksi sellaisenaan, koska bittikentät eivät siirtyisi oikein. Lisäksi C saattaa lisätä tietorakenteen kenttien väleihin tyhjiä alueita (padding), joten varsinainen tietorakenne vie enemmän kuin 20 tavua tilaa muistista.
Wikipedia-artikkelissä olevaa IP-otsaketta esittävää diagrammia
luetaan seuraavasti: kukin rivi esittää 4 tavun (eli oktetin) alueen
otsakkeesta. Kuvan vasemmassa laidassa ja ylälaidassa lasketaan näitä
oktetteja, jotka yhteenlaskemalla tiedät kuinka monta tavua otsakkeen
alkuun pitäisi lisätä jotta pääset käsittelemään kyseistä kohtaa
otsakkeessa. Esimerkiksi protocol-kenttä löytyy 9:n tavun
kohdalta. Jos tavuista muodostettu taulukko buffer esittää
otsaketta, saat protocol-kentän lausekkella buffer[9].
Mukana tulevat tiedostot sisältävät valmiiksi toteutetut funktiot printIp ja hexdump, joita voit käyttää main.c - tiedostossa testataksesi toteutustasi.
Lisävinkkejä:
-
Esimerkiksi alussa oleva Version - kenttä on vain 4 bittiä pitkä. Se tarkoittaa että versio voi saada pelkästään arvoja 0:sta 15:een. Pitäisi siis miettiä miten tavun yläpäähän puristetut bitit saadaan konvertoitua normaaliksi C-kokonaisluvuksi, joka esittää lukua 0:n ja 15:n välillä.
-
IHL-kenttä esittää IP-otsakkeen kokonaispituutta koodattuna neljään bittiin, mutta kenttä esittää pituuden neljän tavun yksikköinä. C-rakenteessa pituus esitetään kuitenkin tavuina. Esimerkiksi IHL-kentässä oleva bittiyhdistelmä 0110 (eli desimaalina 6) tarkoittaa siis otsakkeen pituutena 6*4 = 24 tavua.
-
Kannattaa kiinnittää huomiota C:n laskujärjestykseen binäärioperaatioiden osalta. Bittisiirto-operaatiot
<<ja>>lasketaan esimerkiksi aritmeettisten operaattoreiden (esim. '+' ja '-') jälkeen. Käytä siis sulkeita silloin kun niitä tarvitaan. -
Tietoliikenneprotokollissa 16-bittiset numerot koodataan ns. big-endian - tavujärjestykseen. Tämä tarkoittaa, että kun lukua ajatellaan kahden tavun yhdistelmänä, lukualueen eniten merkitsevä tavu sijoitetaan muistiin (ja edelleen tietoliikennepakettiin) ensiksi, ja vähemmän merkitsevä tavu sen jälkeen. Joudut sijoittamaan tällaiset luvut otsakkeeseen tavu kerrallaan, koska useat järjestelmät (mm. Intel-pohjaiset) käyttävät sisäisesti päinvastaista tavujärjestystä, eli suora kopiointi tuottaa väärän tuloksen.